A modular framework that adapts frozen T2I diffusion models for faithful, causally-grounded counterfactual image synthesis.
"An off-the-shelf T2I diffusion model can be tamed with causal semantic attributes to generate faithful counterfactual images."
+50% intervention effectiveness; +87% image quality (FID) improvement over prior methods.
Fine-tunes in 10 hours on a single NVIDIA A10G (24 GB).
Works with SD 1.5, SD 3, FLUX.1, and future T2I backbones.
Better semantic-spatial alignment in diffusion latents via attention guidance.
Supports learning causal structure (graph) from scratch when none is provided.
Code, data, and fine-tuned models will be publicly available.
We present Causal-Adapter, a modular framework that adapts frozen text-to-image diffusion for counterfactual generation. Our method enables causal interventions on target attributes, consistently propagating their effects to causal dependents without altering the core identity of the image. In contrast to prior approaches that rely on prompt engineering without explicit causal mechanism, Causal-Adapter leverages structural causal modeling augmented with two attribute regularization strategies: prompt-aligned injection, which aligns causal attributes with textual embeddings for precise semantic control, and a conditioned token contrastive loss to disentangle attribute factors and reduce spurious correlations. Causal-Adapter achieves state-of-the-art performance on both synthetic and real-world datasets, with up to 91% MAE reduction on Pendulum for accurate attribute control and 87% FID reduction on ADNI for high-fidelity MRI generation. These results show that our approach enables robust, generalizable counterfactual editing with faithful attribute modification and strong identity preservation.

Current T2I models treat attributes as binary switches. Fine-grained, continuous control (e.g., ventricle volume) is lost in embedding space.
Editing one attribute (age) inadvertently changes others (beard, hairstyle) because T2I latents lack causal disentanglement.
Causal-Adapter's PAI + CTC loss disentangle token embeddings, yielding clean, localized attention maps per attribute.
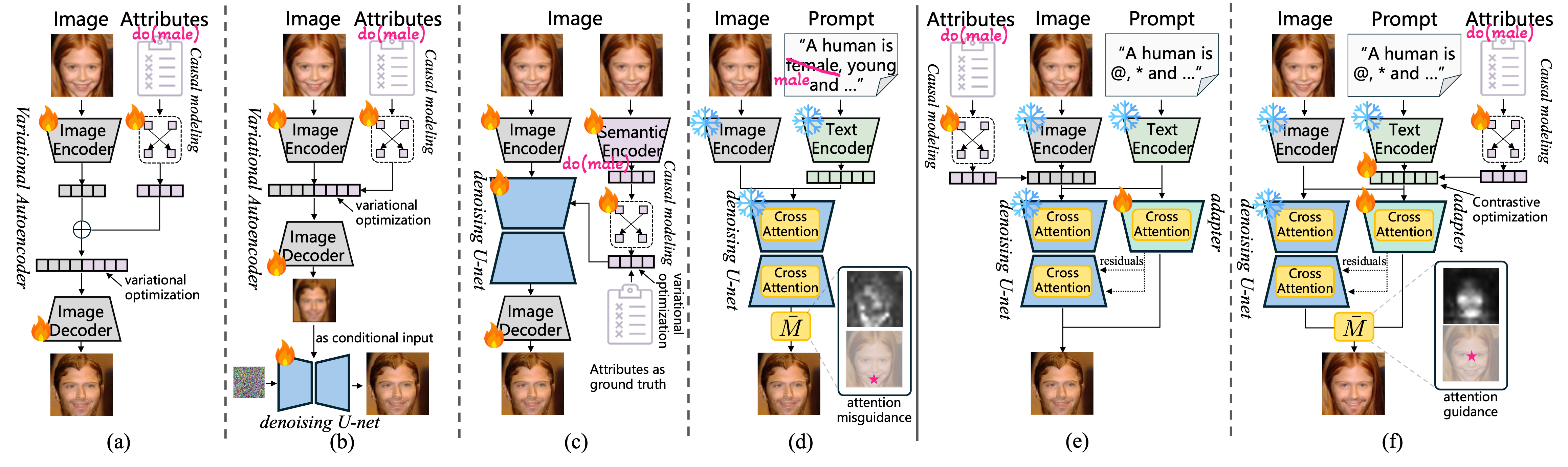
VAE/GAN (a) produce low-fidelity outputs. Diffusion SCM (b) and autoencoders (c) disentangle only in auxiliary encoders, leaving diffusion latents entangled.
Heavy prompt engineering without explicit causal mechanisms. Attention maps misguide edits.
Injects causal attributes into learnable token embeddings with contrastive optimization, achieving both disentanglement and high fidelity.
Causal-Adapter operates in three stages, plugging into a frozen T2I diffusion backbone.
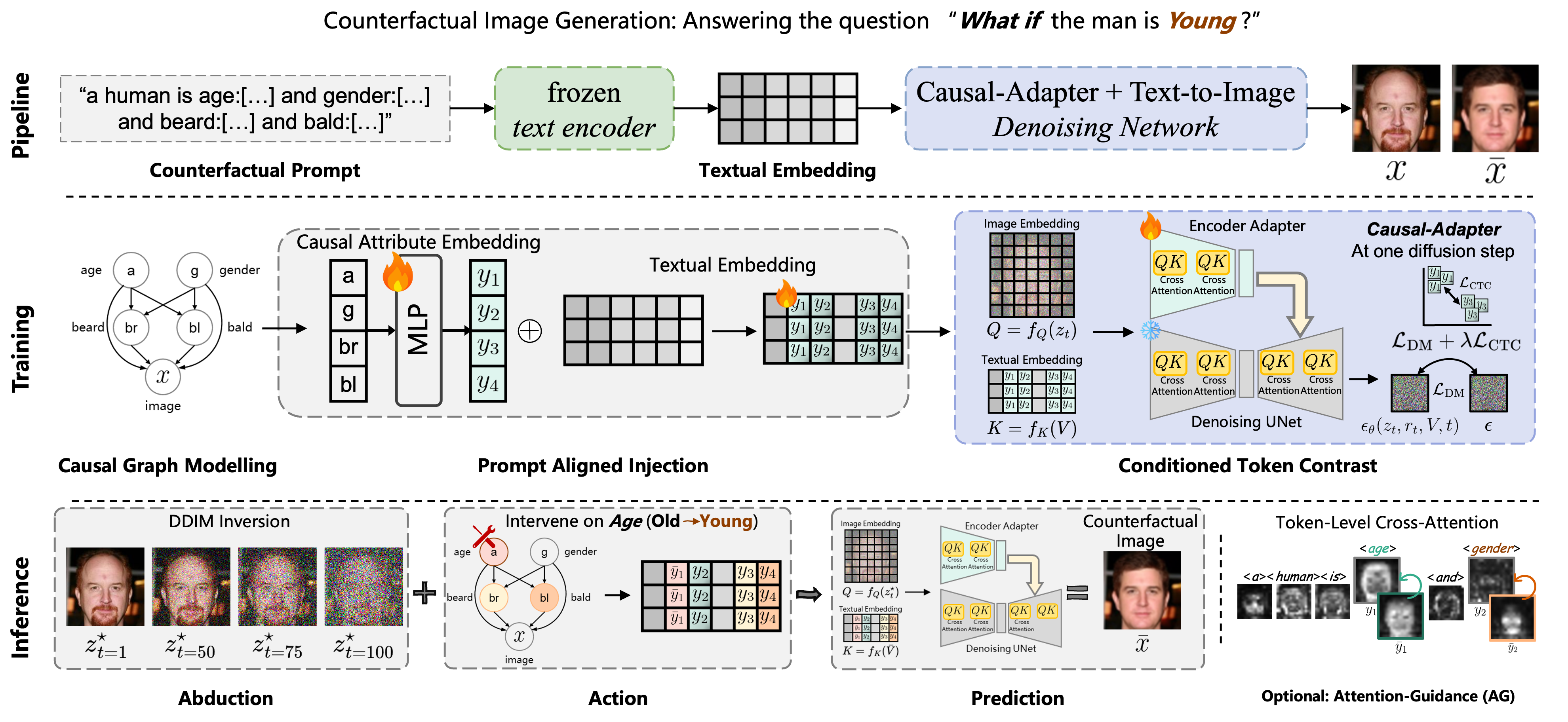
Given a causal graph G and semantic attributes Y, each causal mechanism fi is modeled via a nonlinear MLP with additive noise. The SCM propagates interventions to all downstream variables.
Causal attributes are injected into learnable token embeddings that replace placeholder tokens in the prompt. This aligns causal semantics with spatial features in cross-attention.
An InfoNCE-based loss pulls same-attribute tokens together and pushes different-attribute tokens apart, enforcing disentanglement and reducing spurious correlations.
At inference, abduction-action-prediction is performed via DDIM inversion. Optional Attention Guidance (AG) localizes edits to intervened tokens while preserving identity.
Drag the sliders to intervene on causal attributes and observe how counterfactual images change in response.




Evaluated on 4 datasets: Pendulum (synthetic), CelebA, CelebA-HQ (faces), and ADNI (brain MRI).
Accurate continuous control over pendulum angle, light, shadow length, and shadow position with causal propagation.
Best realism and composition. F1 scores: 99.9% (gender), 58.5% (age), 52.1% (beard).
High-fidelity MRI generation with precise attribute control on age, brain volume, and ventricle volume.
State-of-the-art on eyeglasses and smiling interventions with strong reversibility and identity preservation.
Metrics: Effectiveness (F1/MAE) | Realism (FID) | Composition (LPIPS/MAE) | Minimality (CLD)
@article{tong2025causal,
title={Causal-Adapter: Taming Text-to-Image Diffusion for Faithful Counterfactual Generation},
author={Tong, Lei and Liu, Zhihua and Lu, Chaochao and Oglic, Dino and Diethe, Tom and Teare, Philip and Tsaftaris, Sotirios A and Jin, Chen},
journal={arXiv preprint arXiv:2509.24798},
year={2025}
}
